SAP inzichten creëren met Qlik, Snowflake en AWS.
technische blog over Qlik Cloud Data Integratie
SAP ERP (Enterprise Resource Planning) bevat waardevolle verkooporders, distributie- en financiële gegevens, maar het kan een uitdaging zijn om toegang te krijgen tot en gegevens te integreren in SAP-systemen met gegevens uit andere bronnen om een volledig beeld van het end-to-end proces te krijgen.

Hoe creëer je inzichten uit SAP (ERP) met Qlik, Snowflake en AWS.
Order-to-cash is een kritisch bedrijfsproces voor elke organisatie, met name voor de detailhandel en de productiebedrijven. Het begint met het boeken van een verkooporder (vaak op krediet), gevolgd door het vervullen van die order, het factureren van de klant en tot slot het beheren van de debiteuren voor klant betalingen.
Het vervullen van verkooporders en facturering kan van invloed zijn op de klanttevredenheid, en debiteuren en betalingen hebben invloed op het werkkapitaal en de liquiditeit van contanten. Als gevolg hiervan is het order-to-cash proces de levensader van het bedrijf en is het van cruciaal belang om te optimaliseren.
SAP ERP (Enterprise Resource Planning) bevat waardevolle verkooporders, distributie- en financiële gegevens, maar het kan een uitdaging zijn om toegang te krijgen tot en gegevens te integreren in SAP-systemen met gegevens uit andere bronnen om een volledig beeld van het end-to-end proces te krijgen.
Bijvoorbeeld, het begrijpen van de impact van weersomstandigheden op de logistiek van de supply chain kan directe invloed hebben op de klanttevredenheid en hun bereidheid om op tijd te betalen. Organisatorische silo's en gegevensfragmentatie kunnen het nog moeilijker maken om te integreren met moderne analytische projecten. Dat beperkt op zijn beurt de waarde die u krijgt uit uw SAP-gegevens.
Order-to-cash is een proces dat actieve intelligentie vereist - een staat van continue intelligentie die het triggeren van onmiddellijke acties ondersteunt op basis van real-time, up-to-date gegevens. Het stroomlijnen van deze analytische gegevenspijplijn vereist doorgaans complexe gegevensintegraties en analyses die jaren in beslag kunnen nemen om te ontwerpen en te bouwen - maar het hoeft niet zo te zijn..
- Wat als er een manier was om de kracht van Amazon Web Services (AWS) en zijn kunstmatige intelligentie (AI) en machine learning (ML) engine te combineren met de rekenkracht van Snowflake?
- Wat als u een enkel Qlik software-as-a-service (SaaS) platform zou kunnen gebruiken om de automatisering van de inname, transformatie en analyse voor enkele van de meest voorkomende SAP-gerichte zakelijke transformatie-initiatieven te realiseren?
- Wat als leveranciers en retailers/fabrikanten beter konden samenwerken door wederzijdse toegang tot realtime data mogelijk te maken via de gegevensuitwisselings- en marktplaatsmogelijkheden van Snowflake?
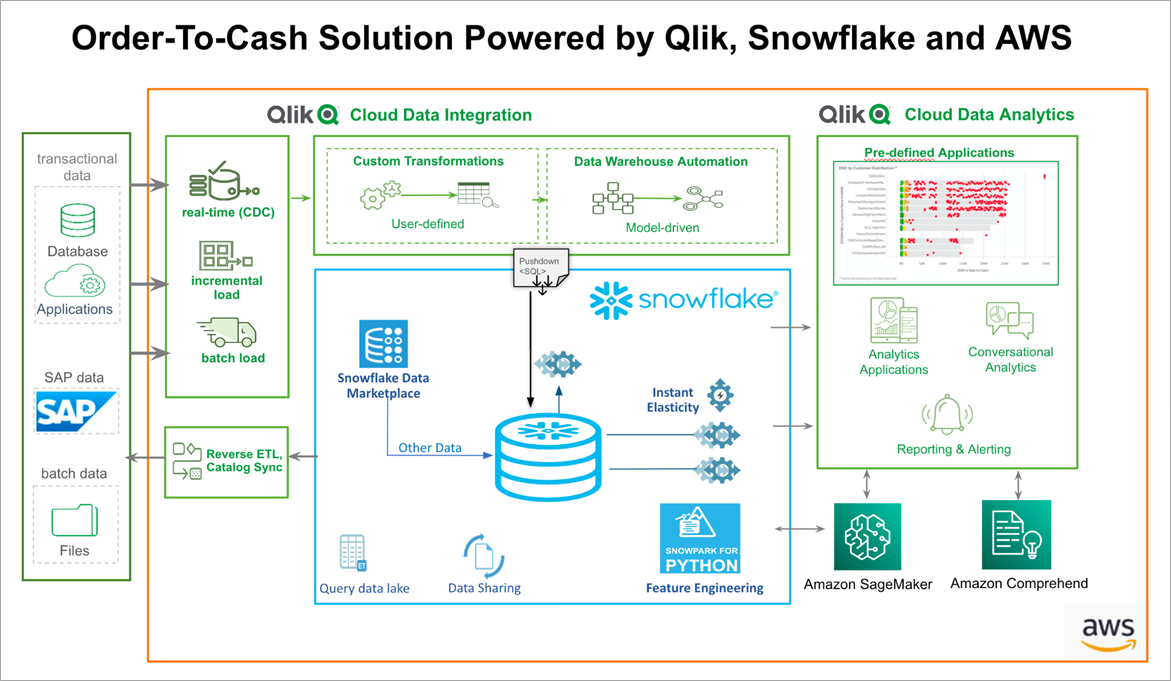
In deze blog, bespreken we Qlik Cloud Data Integration accelerators voor SAP in samenhang met Snowflake en AWS.
Qlik Cloud Data Integration
Qlik Cloud Data Integration accelerators integreren met Snowflake om de ontsluiting, transformatie en analyse te automatiseren en zo enkele van de meest voorkomende SAP problemen op te lossen. Dit stelt gebruikers in staat om zakelijke inzichten af te leiden die besluitvorming kunnen stimuleren..
{kind=link}
Qlik biedt een enkelvoudig platform voor het extraheren van gegevens uit SAP en laadt de gegevens in Snowflake als gegevensopslagplaats. Qlik houdt de gegevens gesynchroniseerd met zijn gateway voor wijzigingsgegevensopname (CDC) die de transformatiemotor voedt, waardoor Qlik de ruwe SAP-gegevens kan converteren naar bedrijfsvriendelijke gegevens die gereed zijn voor analyse.
Qlik maakt gebruik van zijn Qlik Cloud Analytics-service op de SAP-gegevens om analyse en visualisatie mogelijk te maken, en om gegevens in Amazon SageMaker te voeden om voorspellingen te genereren met de kunstmatige intelligentie (AI) en machine learning (ML) engine.
Snowflake: de Data Collaboration Cloud
Snowflake heeft AWS-competenties op het gebied van data en analytics, evenals machine learning, en heeft de data cloud opnieuw uitgevonden om te voldoen aan de digitale transformatiebehoeften van vandaag. Organisaties in verschillende sectoren maken gebruik van Snowflake om gegevens te centraliseren, te beheren, samen te werken en bruikbare inzichten te genereren.
Hier zijn de belangrijkste redenen waarom organisaties Snowflake vertrouwen met hun gegevens:
- Snowflake is een cloud- en regio-onafhankelijke data cloud. Als de SAP-gegevens van een klant bijvoorbeeld worden gehost op AWS, kunnen ze Snowflake op AWS provisioneren en AWS PrivateLink gebruiken voor veilige en directe connectiviteit tussen SAP, AWS-services en Snowflake.
- Scheiding van rekenkracht en opslag stelt gebruikers in staat om granulaire controles en isolatie toe te passen, evenals op rollen gebaseerd toegangsbeheer (RBAC) beleid voor verschillende soorten workloads. Dit betekent dat extract, transform, load (ETL) taken geïsoleerde berekeningen kunnen hebben ten opzichte van kritieke business intelligence (BI) rapporten ten opzichte van feature engineering voor machine learning, en gebruikers hebben controle over hoeveel berekening er aan elke van deze workloads wordt besteed.
- Een bloeiende data marketplace om klantgegevens te verrijken met aanbiedingen van derden. De marketplace maakt veilige gegevensdeling intern en extern mogelijk, zonder dubbele kopieën van gegevens te maken.
- Een sterk tech-partner ecosysteem dat best-of-breed producten biedt in elke datacategorie: data-integratie, datagovernance, BI, data-observability, AI/ML.
- • Mogelijkheid om code naar gegevens te brengen, in plaats van gegevens te exporteren/verplaatsen naar afzonderlijke verwerkingssystemen, via Snowpark. Code in Java, Scala of Python wordt opgeslagen in Snowflake.
Joint Solution Overview
Laten we ons verdiepen in een SAP business use case die alle bedrijven delen - orders tot betaling. Dit proces in SAP omvat meestal het verkoop- en distributiemodel, maar we hebben accounts payable toegevoegd om het verhaal compleet te maken.

De SAP accelerators maken gebruik van vooraf gebouwde logica om ruwe SAP-gegevens om te zetten in bedrijfsgerichte analyses. Het begint met het verkrijgen van de gegevens uit SAP; je kunt Qlik Data Gateway - Data Movement implementeren en installeren in de buurt van het SAP-systeem om de gegevens uit SAP te halen en deze in Snowflake te plaatsen, zonder de prestaties van het SAP-productiesysteem te beïnvloeden.
{kind=link}
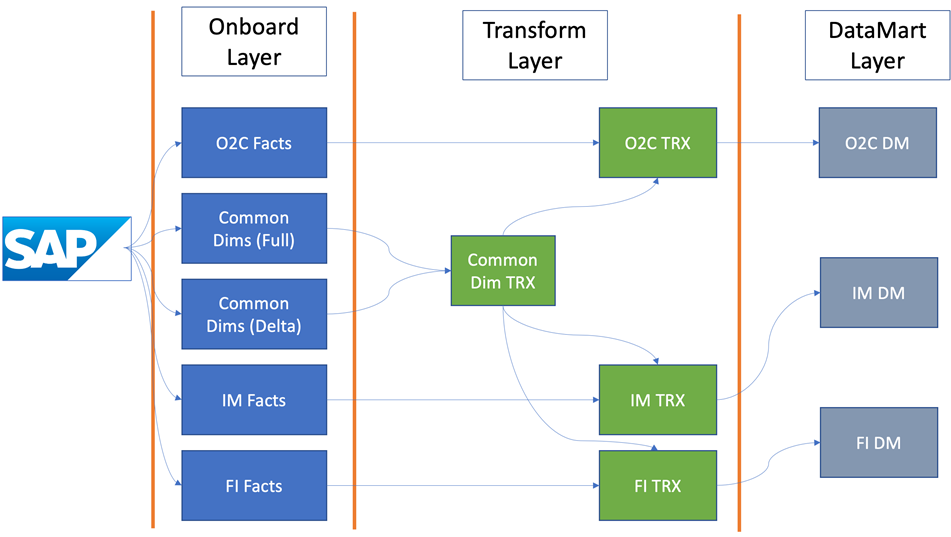
Voor de SAP accelerators hebben we de SAP extractors gebruikt als basis voor de gegevenslaag. Deze vooraf getransformeerde gegevens stellen ons in staat om slimmere methoden te gebruiken om gegevens uit SAP te halen. Voor het gebruiksscenario order-to-cash hebben we 28 extractors nodig, wat meer dan 200+ tabellen zou zijn als we rechtstreeks naar de onderliggende SAP-structuur zouden gaan.
Met behulp van een enkelvoudig eindpunt halen we de gegevens uit SAP naar Snowflake en partitioneren we de feitelijke gegevens per gebruiksscenario, maar we gebruiken een gemeenschappelijke set dimensies om de scenario's te voeden. Hieronder ziet u hoe deze architectuur er conceptueel uitziet.

Dit proces maakt gemakkelijke toekomstige toevoeging van nieuwe SAP-use cases mogelijk.
{kind=link}
Met ons enkele eindpunt kunnen we tegelijkertijd gegevens laden in onze landing- en opslaggebieden. De gegevens worden slechts één keer geland en Qlik gebruikt zoveel mogelijk views om gegevensreplicatie binnen Snowflake te voorkomen.
Nu hebben we twee verschillende dimensionale ladingen en sommige dimensies zijn niet CDC-ingeschakeld (genaamd Delta). Die worden op een schema opnieuw geladen en samengevoegd met de Delta-dimensie in een transformatielaag, die een enkele set entiteit presenteert voor de constructie van de datamartlaag.
Laten we eens kijken naar het proces voor orders tot cash. We landen en slaan de gegevens op in Snowflake, en in de landing laag voegen we de regels toe die de namen en kolommen van de SAP-extractors omzetten in gebruikersvriendelijke namen.

Je zou kunnen opmerken dat er veel regels zijn. We hebben een rapport uitgevoerd in SAP om alle metadata te extraheren via extractors, maar niet alle namen zijn hetzelfde. KUNNR is bijvoorbeeld ship-to-klant in de ene extractor en sold-to-klant in een andere.
Elke extractor heeft zijn eigen definitie en we hebben Qlik Sense gebruikt om een metadata-woordenboek te maken dat we kunnen toepassen in de gebruikersinterface (UI).

Zoals u kunt zien, gebeuren er tegelijkertijd verschillende belangrijke zaken. Binnen deze no-code UI hebben we ongeveer 80+ extractors naar een landing area geleid, hernoemd en weergaven toegevoegd met vriendelijke namen in de store-laag.
Dit is belangrijk omdat veel SAP-oplossingen stromen of codering vereisen voor elke extractor of tabel als een individueel stukje code om te onderhouden, maar binnen Qlik wordt alles simultaan beheerd via de SaaS-UI (geen codering vereist).
Zodra de gegevens correct zijn geïndexeerd en hernoemd, beginnen we met het uitvoeren van onze transformatielagen. Dit proces combineert de dimensie tot één entiteit en creëert het bedrijfsspecifieke proces voor een use case zoals orders to cash.
De transformatielaag is waar we de gegevens gaan manipuleren met 100% pushdown SQL naar Snowflake. Enkele voorbeelden van transformaties zijn het draaien van valuta, het afvlakken van beschrijvende tekst en andere SQL-manipulaties.
Naast de SQL-manipulaties werd er ook een Python Snowpark-stored procedure gemaakt in Snowflake en aangeroepen via de Qlik SQL pushdown. Dit toont aan hoe ingenieurs die bekend zijn met de Python-taal, transformatiestappen kunnen bouwen als een opgeslagen procedure in Snowflake en het kunnen benaderen via Qlik.
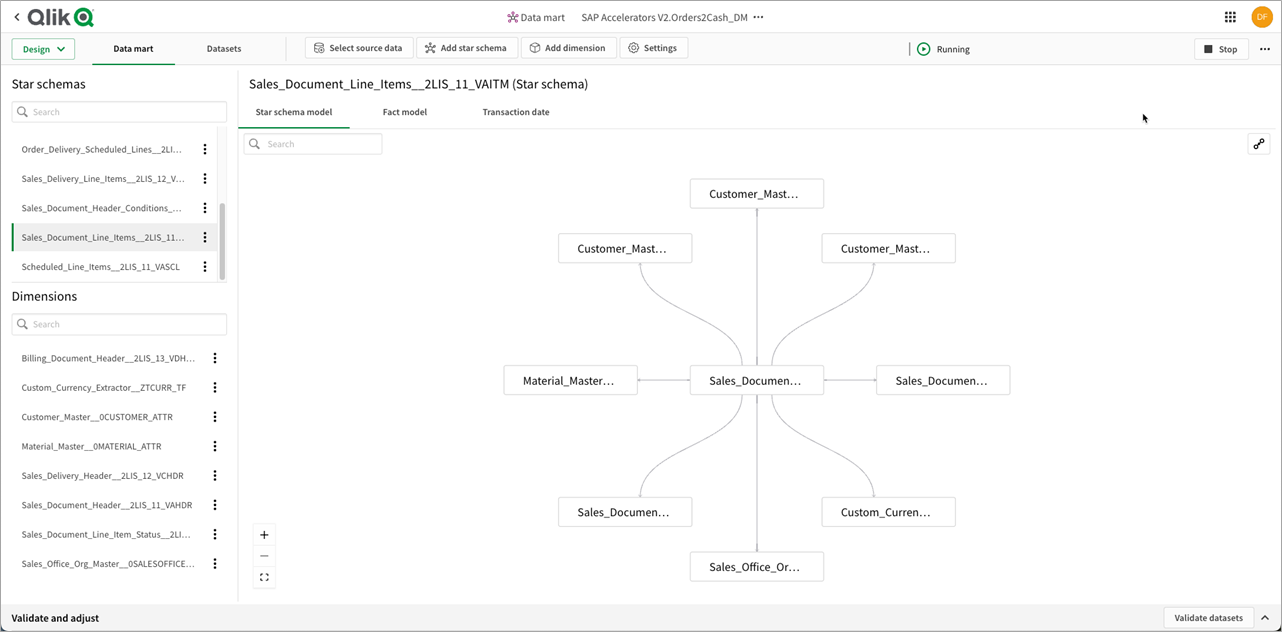
Zodra de gegevens volledig zijn gemapt, getransformeerd en voorbereid, creëren we de definitieve state data mart-laag. Qlik Cloud Data Integration vlakt de dimensionale vlokken uit tot een echte sterrenschema gereed voor analyse, en deze sterrenschema's worden geconsolideerd onder een enkele datamartlaag per bedrijfsproces.

Onze gegevenslaag is nu compleet. We hebben het Qlik Cloud Data Integration SaaS-platform gebruikt om gegevensmarts te laden, op te slaan, te transformeren en te leveren die klaar zijn voor analyse om onze Qlik SaaS-analysemotor te voeden.
{kind=link}
De SAP-acceleratoren worden geleverd met modules voor order-to-cash, voorraadbeheer, financiële analyse en procure-to-pay.

SAP from Raw to Ready Analytics
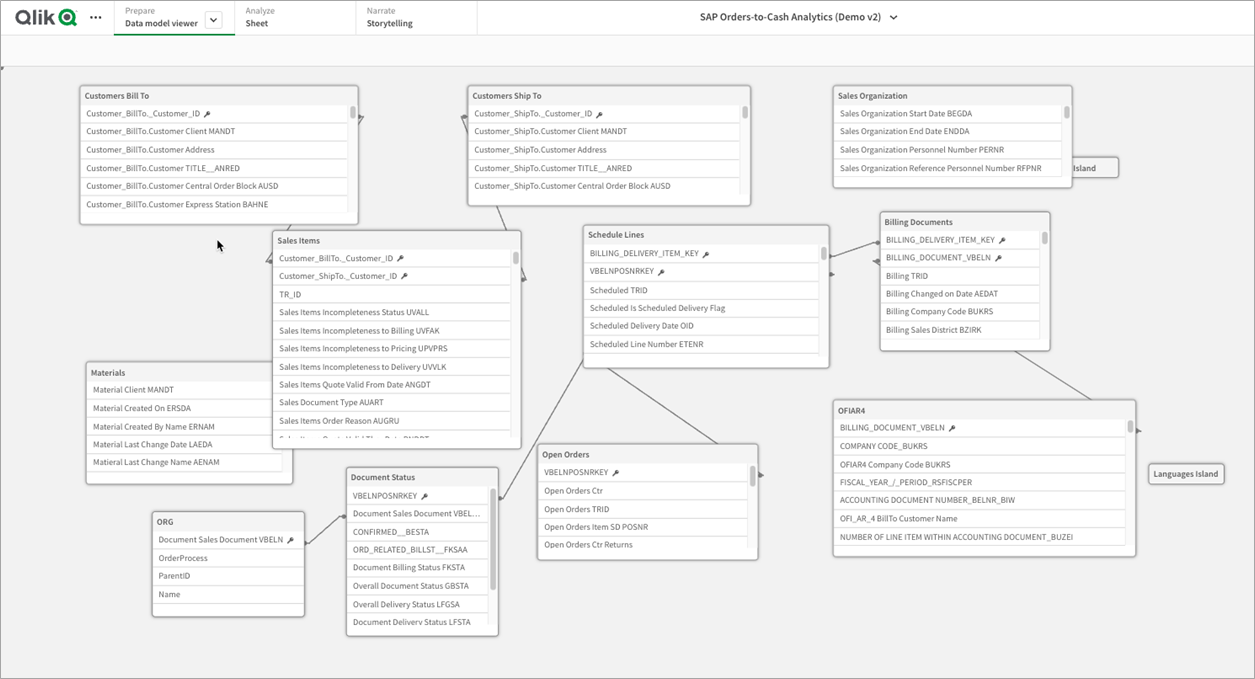
Met de gegevensvoorbereiding afgerond, kunnen we nu de kracht van Qlik SaaS-analyse toevoegen. We halen alle sterschema's van de datamart-laag binnen in Qlik en creëren een semantische laag boven op de pure SQL-gegevens.
De associatieve engine van Qlik wordt gebruikt om alle onderdelen van het order-to-cash module samen te voegen in een samenhangend in-memory model. We voegen ook master measures en online analytische verwerking (OLAP)-achtige complexe setanalyse-berekeningen toe om dynamische gegevensentiteiten te creëren, zoals rollende datums of complexe berekeningen zoals de dagen omzet uitstaand.
Hier ziet het verfijnde analysemodel eruit in Qlik SaaS. Merk op dat er meerdere feitentabellen (10) zijn die die gemeenschappelijke set dimensies delen.

{kind=link}
Toegang hebben tot al die gegevens stelt ons in staat om het grotere plaatje te zien rond het proces van orders tot betaling in SAP.

SAP Order-to-Cash Analytics
De zakelijke vraag van hoe een bestelling verloopt van het product dat besteld is, tot wanneer het verzonden is, tot wanneer het gefactureerd is, tot wanneer de klant betaald heeft, is waarvoor het order-to-cash module is ontworpen om te beantwoorden. Laten we eens kijken naar een bestelling die een klant heeft geplaatst. Die bestelling (5907) werd in eerste instantie geplaatst op 17-06-1999 en de betaling werd voltooid op 12-12-1999. Dat is een dagen sales outstanding (DSO) van 194 dagen! Dat zou het einde van de vraag zijn bij het gebruik van een eenvoudige SQL-gebaseerde query tool, maar met het Qlik associatieve model kunnen we zien wat er is gebeurd.

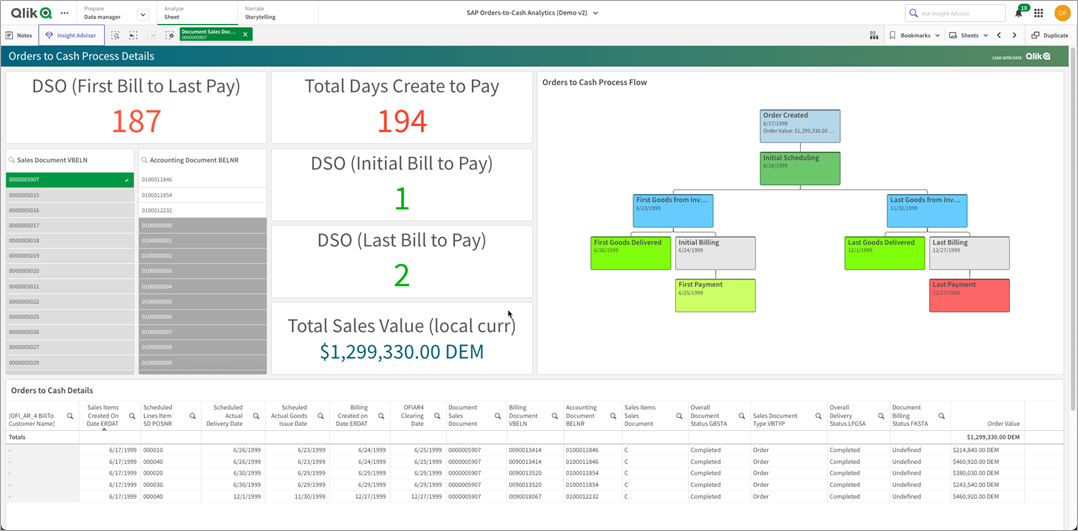{kind=link}
Er was niet genoeg materiaal op voorraad om de hele bestelling te verzenden, dus werd deze opgesplitst in drie aparte zendingen en betaald via drie documenten. Technisch gezien was de DSO (Days Sales Outstanding) 194 dagen, maar van factuur tot betaling waren het slechts 187 dagen. Dit is echter niet het hele verhaal. De klant betaalde namelijk binnen 1-2 dagen na facturatie. Deze details zouden niet naar voren zijn gekomen zonder gebruik te maken van de Qlik-analysemotor.
Zelfs in dit gebruiksscenario kijken we alleen terug naar wat er is gebeurd. Maar wat als we vooruitkijken en trends identificeren? Bijvoorbeeld, als bepaalde onderdelen niet op voorraad zijn, kunnen we niet alles in één keer verzenden. Met Amazon SageMaker kunnen we voorspellen welke problemen en vertragingen we kunnen verwachten.
Met de SAP-versnellers hebben we plug-and-play-sjablonen gemaakt om de moeilijke vragen te stellen over SAP-gegevens, met Snowflake en AWS als de motoren die de inzichten aandrijven met het Qlik SaaS-platform.
Predicting the Future with Amazon SageMaker
Een van de krachtigere componenten van de Qlik SaaS-architectuur is de mogelijkheid om de data in de Qlik-applicatie te integreren met de Amazon SageMaker-engine. In ons order-to-cash gebruiksgeval hebben we voorbeeldgegevens genomen en een SageMaker-model getraind om voorspellingen te doen over te late versus op tijd geleverde orders.
Een snelle manier om dit te bereiken is door gebruik te maken van de Snowpark API om feature engineering op het dataset uit te voeren, voordat de data uiteindelijk wordt ingebracht voor training en implementatie naar een SageMaker endpoint. Vervolgens kunnen we voor inferentie Qlik gebruiken om toegang te krijgen tot het endpoint en voorspellingen rechtstreeks in het dashboard te presenteren.
Hoe werkt dit met analytics? Binnen Qlik SaaS kunnen we een verbinding maken met Amazon SageMaker om data vanuit de Qlik-engine door te geven aan een endpoint dat de eerdergenoemde voorspellingen zal doen op basis van de SAP-gegevens.
Wanneer de data opnieuw wordt geladen in de Qlik-analytics engine, voedt het data van relevante in-memory tabellen als dataframes in het SageMaker endpoint waar de AI/ML-voorspelling zal worden berekend. De voorspellingen worden teruggegeven aan de Qlik-app en opgeslagen in de cache samen met de originele data, en zijn beschikbaar voor de visualisatielaag om te presenteren.

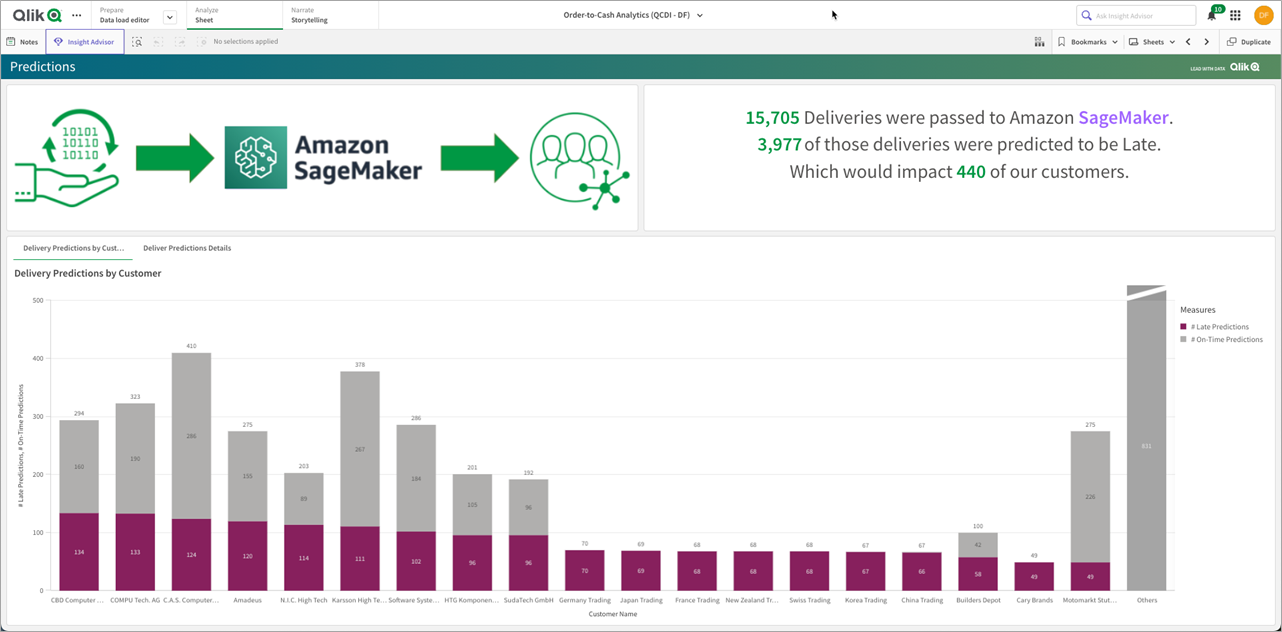{kind=link}
We hebben nu de cyclus voltooid van het verzamelen van historische gegevens uit SAP en het bewerken en omzetten in gegevens die gereed zijn voor analyse met behulp van Qlik Cloud Data Integratie. We hebben ook deze verfijnde gegevens gepresenteerd met Qlik Cloud Analytics en toekomstige resultaten voorspeld met Amazon SageMaker - dit alles draaiend op de Snowflake data cloud.
Conclusie
In een typische orderbeheercyclus is het delen van informatie tussen organisaties van cruciaal belang geworden voor een succesvolle werking van moderne ondernemingen. Verbeterde klanttevredenheid, verhoogde concurrentiekracht en de vermindering van knelpunten in de toeleveringsketen en dagen verkoop uitstaand zijn belangrijke indicatoren voor een geoptimaliseerde cashflow voor het bedrijf.
In deze post bespreken we hoe de Qlik Cloud Data Integration SAP accelerator-oplossing, in samenwerking met Snowflake en AWS, uw SAP-data modernisering kan versnellen, meer flexibiliteit en samenwerking tussen organisaties mogelijk maakt en snel zakelijke oplossingen kan leveren door geoptimaliseerde order-to-cash bedrijfsinzichten.
Om meer te weten te komen, neem dan contact op met onze verkoopafdeling om het volledige potentieel van uw SAP-data te realiseren.
Download Blog
Download hier de volledige blog
